It allows to keep PV going, with more focus towards AI, but keeping be one of the few truly independent places.
-
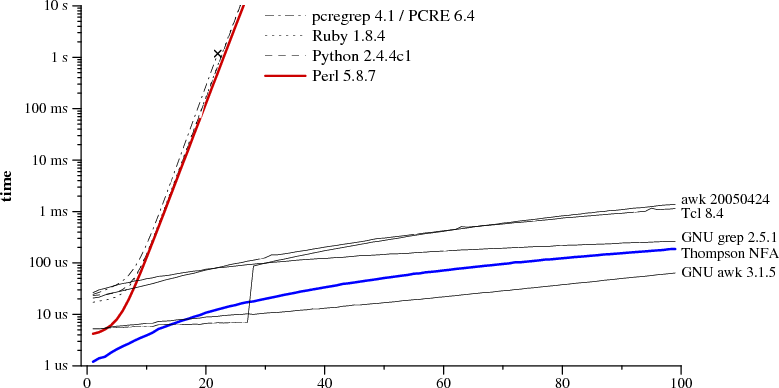
Interesting thing, isn't it? PHP here is PCRE. Blue line is algorithm proposed (and used as you can see in some tools) long long time ago.
Good illustration to our current approach - hardware is cheap, let's install more powerful server. :-) -
It is kind of fascinating. Doesn't it mean actually that we have kind of comfortable life with our PCs only for the reason of incredibly fast working CPUs of today? Interesting that also Java belongs to the list of slowness....
-
No, it is specific thing for processing strings.
It is performance of algorithm, language play second role here. -
Interesting, though I had to check the link to find out what the horizontal axis is actually plotting ;)
-
Are you thinking of building a search engine from scratch?
Seriously, nobody* does full-pattern matches. Web servers employ an indexing method like Swish-E which reduce the stack of text Grep needs to look through by n(-100).
Then, of course, PV's current implementation of Google's Big Table database and search algorythms is working well, thanks. It's making free use of the Google Dance of indexing the world's data while we sleep.
*Hackers probably make use of fast pattern-matching.
-
Google Big Table? Was PV built on Google App Engine?
-
@stonebat No, only that PV's search box now does a Google site search. I've worked in companies and departments where if you want to find out what your own job is it's lots easier to google the department's website than to use your in-house search engine!
There are a few downsides to using Google search in house but it's free and a bit of a no-brainer for most mortals.
Seriously, nobody* does full-pattern matches.
Hackers probably make use of fast pattern-matching.
[Edit: silly me] As I type I'm watching Saturday Night's Antenne 2 Week-end TV news where big corporations are using fast pattern matching to search all employees' emails. Talk about serendipity!
Come to think of it, Echelon probably does something pretty similar :-(
-
Yeap they know you haha
-
Seriously, nobody* does full-pattern matches. Web servers employ an indexing method like Swish-E which reduce the stack of text Grep needs to look through by n(-100).
I fail to understand that you mean and how web servers and grep are related here.
Article and chart is about regular expression performance, and believe me, tons of them are used in almost every web framework, CMS, forum, etc.
-
@Vitaliy_Kiselev I have installed lot of web search engines from simple Open Source like Joomla and Drupal through to enterprise itranet/internet CMS using MySource Matrix and Squiz. All of them rely heavily on indexing and use grep-derived libraries, despite their perceived slowness, to search through normalised (therefore indexed)SQL tables.
The DBMS itself (Oracle, PostgreSQL, etc) has commands which can return related results in milliseconds. Big Social Media sites like You Tube and Face Book will be using whatever they can to return results to users' queries over distributed networks. I don't know what they're using and they'd be stupid to tell us. (Maybe they're grepping raw text for some reason?)
With Blekko you can indeed use a Grep Gui like Web Grepper - which once again uses indexation to perform very fast searching using relatively slow, Grep.
Like PHP and Perl, other scripting languages incorporate database search libraries but I don't see anywhere Thompson's Construction Algorithm gets implemented on web servers. If you can give me an example, it might make it clearer.
-
I have installed lot of web search engines from simple Open Source like Joomla and Drupal through to enterprise itranet/internet CMS using MySource Matrix and Squiz. All of them rely heavily on indexing and use grep-derived libraries, despite their perceived slowness, to search through normalised (therefore indexed)SQL tables.
No one it talking about search engines here.
Again, it is just article about regular expressions and application and scripts use ton of this, believe me, I saw many on them inside.
As for site search engines, most of them are just horrible from my personal expirience.
-
Are you thinking of building a search engine from scratch?
My first question said it all.
OK not for a web server! I understand.
OK: would the regular expression scripting be for a database back-end, then?
-
I have big trouble understanding all this search engine stuff you constantly bring up.
I did not mentioned any search engines, and did not even thinked about it, they are not related here.
-
I have big trouble understanding all this search engine stuff you constantly bring up.
Sorry I couldn't have simplified my first question. A simple, "No" would have sufficed.
Can you please explain how you'd like to make use of the faster algorithms? Do you mean something other than searching per se? A smarter image compression algorythm?
-
Can you please explain how you'd like to make use of the faster algorithms? Do you mean something other than searching per se? A smarter image compression algorythm?
I do not like to "make use of the faster algorithms". I just found interesting article I'd like to share, so many people will understand why sometimes their PHP scripts struggle badly, it is especially the case for systems using on the fly formatting.
-
This paper is about one pathological class of regular expressions. They're very uncommon.
-
It is wrong view. It is about how regular expressions are implemented.
It is also useful to understand that most formatters are made using regular expressions (that by itself is not fast, plus they in their turn have flaws in implementation as shown in paper), and not as state machines. This things you are using every day hundreds of times (but do not know about it).
-
hardware is cheap, let's install more powerful server. :-)
Oh OK @Vitaliy_Kiselev, I finally get it that you were being satirical here. A ;-) wink would have helped me better than the smiley ;-) You were not intending to use Thompson's Construction Algorithm to build a faster web server at all, but throw more brute power at the existing inefficient work the server is performing.
Yes, just like Betamax and VHS, we've thrown our computing power behind the inferior algorithm - and overlooked TCA pattern matching all along until it's probably almost obsolete.
-
The chart shows the time to match the regular expression a?^na^n against certain text n characters long using a few different matching algorithms. The whole point of the paper is that for this weird class of regular expression with certain text input, some of the algorithms are ridiculously slow compared to some other algorithms. It takes more than 10 seconds to match the regular expression against text 25 characters long, and the time grows exponentially with n. Think about that for a second. It would be impossible to match a regular expression against even a single page of text. The processing would never finish.
If these pathological regular expressions were common, Perl and Ruby and Python would have switched to one of the faster algorithms a long time ago. But these regular expressions are exceedingly uncommon, so it's just not that big of a deal. Once in a while you run into one of those pathological cases. It causes the processing to be ridiculously slow or to not finish at all, you find the problem, and then you rewrite the regular expression to avoid the problem.
The author's stance is that Perl should be able to detect and avoid the pathological cases, and he's certainly got a point there. But none of what he's talking about - absolutely none of it - generalizes to the performance of regular expression matching algorithms for anything but these weird pathological cases.
-
Again, I do not agree here. As point of article is about implementation. And usage of expressions that are the bound case to illustrate point is absolutely normal.
Here is one more link http://lh3lh3.users.sourceforge.net/reb.shtml
-
This from another article from link I provided in last post
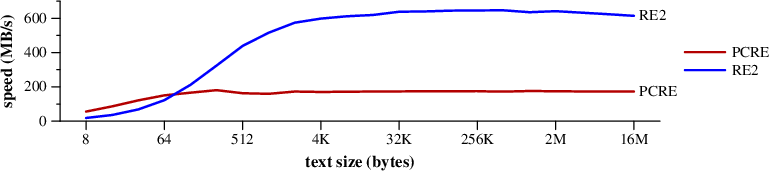
Speed of searching for ABCDEFGHIJKLMNOPQRSTUVWXYZ$ in random text. (Mac Pro):
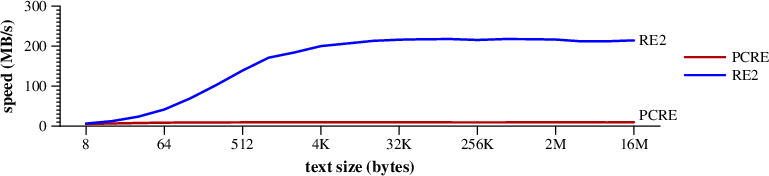
Speed of searching for and matching (\d{3}-|(\d{3}\)\s+)(\d{3}-\d{4}) in random text ending wtih (650) 253-0001. (Mac Pro) :
-
The benchmarks you just linked show the backtracking algorithm having better performance than finite state automata on most of that sampled real-world input. The backtracking algorithms are the slow ones in the first paper.
It's not really hard to find examples where one algorithm or the other performs better. But which one performs better for the regular expressions that you are using and the kinds of input that you process? That's what matters.
-
The benchmarks you just linked show the backtracking algorithm having better performance than finite state automata on most of that sampled real-world input.
LOL.
According to table most consistent result showed by RE2. With one of expressions giving almost 20x advantage compared to fastest backtracking (that performed good for others).
And author in first link specially mentioned that he used only short lines from big text.
Second link talk about longer text.
Small addition.
PCRE is also good implementation. And if you need to run matches for long texts, and also with certain regexps (mostly with many ORs as I understood it) it is always good to check FSA implementations.
-
Btw, check this








Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- Topics List23,992
- Blog5,725
- General and News1,354
- Hacks and Patches1,153
- ↳ Top Settings33
- ↳ Beginners256
- ↳ Archives402
- ↳ Hacks News and Development56
- Cameras2,367
- ↳ Panasonic995
- ↳ Canon118
- ↳ Sony156
- ↳ Nikon96
- ↳ Pentax and Samsung70
- ↳ Olympus and Fujifilm101
- ↳ Compacts and Camcorders300
- ↳ Smartphones for video97
- ↳ Pro Video Cameras191
- ↳ BlackMagic and other raw cameras116
- Skill1,960
- ↳ Business and distribution66
- ↳ Preparation, scripts and legal38
- ↳ Art149
- ↳ Import, Convert, Exporting291
- ↳ Editors191
- ↳ Effects and stunts115
- ↳ Color grading197
- ↳ Sound and Music280
- ↳ Lighting96
- ↳ Software and storage tips266
- Gear5,420
- ↳ Filters, Adapters, Matte boxes344
- ↳ Lenses1,582
- ↳ Follow focus and gears93
- ↳ Sound499
- ↳ Lighting gear314
- ↳ Camera movement230
- ↳ Gimbals and copters302
- ↳ Rigs and related stuff273
- ↳ Power solutions83
- ↳ Monitors and viewfinders340
- ↳ Tripods and fluid heads139
- ↳ Storage286
- ↳ Computers and studio gear560
- ↳ VR and 3D248
- Showcase1,859
- Marketplace2,834
- Offtopic1,320
Tags in Topic
- idiots 102


